
About a month ago (can it have been that long already?) I started an effort to try to baseline EXA performance on an r100 chip. A particularly alarming result from that initial test was that cairo's rectangles case was running 14 times slower with EXA than with no X server acceleration at all.
Afterwards, Eric and Dave set me straight and I got DRI working with EXA. This definitely made it faster in general, but the rectangles test was still 8x slower than NoAccel. A deeper look was necessary.
Eric had various theories about how cairo's measurement strategy could be confounding the results. What cairo's performance suite does is to perform an XGetImage of a single pixel as a synchronization barrier, (to allow the suite to wait until the X server provides the result as a guarantee that all pending rendering has occurred). One theory is that EXA could be doing something extremely inefficient here, (such as fetching the entire image instead of just a single pixel).
To alleviate this possible problem, I cranked the number of rectangles being rendered between timings from 1000 to 10000. This actually did help to some extent. After this change EXA is only 2-3x slower than NoAccel instead of 8x slower.
Also, we noticed that this slowdown only occurs when drawing to an ARGB Pixmap as opposed to drawing to an RGB Window, (when drawing to a window EXA is about 4x faster than NoAccel, whether drawing 1000 or 10000 rectangles).
So the test with 1000 rectangles was definitely measuring something undesired, since a 10x increase in the the number of rectangles resulted in something close to a 2x increase in rendering time. (For EXA to a Pixmap at least---EXA to a Window, and NoAccel to a Window or Pixmap all increased by about 10x). I'm still not sure exactly what the problem was in the case with 1000 rectangles, but the 1x1 XGetImage is still a possibility. Eric has suggested adding a new wait-for-rendering-to-complete request to the XFixes extension to eliminate the need for the 1x1 XGetImage and any problems it might be causing.
After seeing the results change so dramatically with the number of iterations, I began to wonder about batching effects. The original cairo-based rectangles test case looked about like this:
for (i = 0; i < NUM_RECTANGLES; i++) {
cairo_rectangle (cr, rect[i].{x,y,width,height});
cairo_fill (cr);
}
That is, each rectangle was being filled individually. I experimented
with changing this so that many calls were made to cairo_rectangle for
each call to cairo_fill. The mysterious EXA slowdown I had been
chasing went away, but only because everything became a lot slower. It
turns out there's a bad performance bug in cairo when it converts from
a list of rectangular trapezoids to a pixman_region. Cairo's pixman
doesn't expose a function for "create region from list of rectangles"
so cairo is calling a pixman_region_union function once for every
rectangle. This looks like an unnecessary O(n**2) algorithm to
me. Fortunately that should be a simple thing to fix.
So next I rewrote the test case by eliminating cairo calls and calling directly into either XRenderFillRectangles or XFillRectangle. I was shocked to find that the Render function was much slower than the non-Render function, (with no change in the X server). A little protocol tracing[*] revealed that XFillRectangle is batching requests while XRenderFillRectangles is not. That's a rather nasty trap for an unwary Xlib coder like myself. I added batching in chunks of 256 rectangles around XRenderFillRectangles and it started behaving precisely like XFillRectangles.
Finally, I eliminated some non-determinism from the rectangles test case. Originally, it was written to choose randomly-sized rectangles by independently selecting a width and height from 1 to 50. Instead I ran separate tests at power-of-2 sizes from 1 to 512. The results of doing this were quite revealing and are best seen graphically:
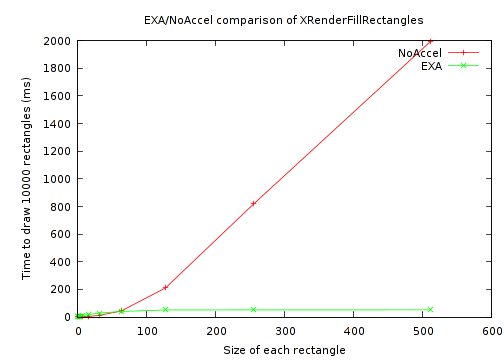
And a closer look at the small rectangles:
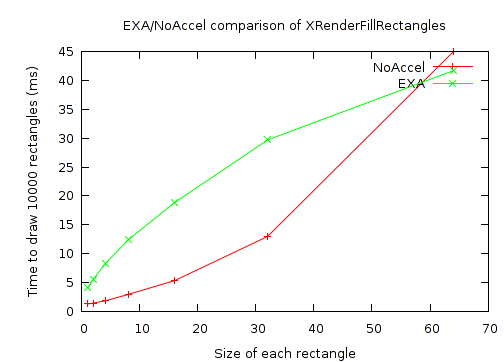
As can be seen, there's a break-even point at a rectangle size just below 60x60. Above that, EXA performance scales extremely well, with the time becoming flat based on the number of rectangles, and independent of their size. While NoAccel performance scales quite poorly (and as expected).
Meanwhile, for the small rectangles, (which my original test case just happened to be testing exclusively), EXA is 3 to 4 times slower than NoAccel. Perhaps it would make sense for the X server to take an alternate approach for these small rectangles? The NoAccel results show that the X server does have faster code already. Or perhaps EXA itself could be made faster by having some hardware state caching to reduce overhead from one rectangle to the next.
But there are some obvious questions here: What sizes actually matter? What would a rectangle-size histogram look like for typical desktop loads? There's definitely room to do some measurement work here so that we can come up with meaningful benchmarks, (rather than the fairly arbitrary things I started with), and focus on optimizing the things that really matter.
A similar issue holds for the batching issue. I only saw good performance when I batched many rectangles into each call to XRenderFillRectangles. But is that even a reasonable thing to expect applications to be able to do? Do applications actually sequentially render dozens of rectangles all of the same color? I'm imagining GTK+ widget themes with bevelled edges where it's actually much more likely that the behavior would be close to toggling back and forth between two colors every one or two rectangles. And that kind of behavior will exhibit wildly different results than what's being benchmarked here.
Anyway, there's plenty of interesting work to still be done here.
[*] I used wireshark and manually decoded all Render requests. I'm looking forward to good protocol tracing tools that decode all extensions. And yes, I'm aware of current XCB efforts to provide this---should be very nice!