
Earlier this month I attended the X Developers' Summit in Cambridge, UK (not the Cambridge near Boston, USA). We stayed at Clare College which, like all of the University of Cambridge colleges that I saw, is immaculately well-kept and quite beautiful. Just look at the gardens I walked past every day to get from my room to the conference room in the library. Kudos to the X.Org foundation for arranging such a beautiful site, (I think Daniel Stone and Matthew Garrett deserve particular thanks), and for providing travel expenses so I could attend.
Adam "ajax" Jackson was kind enough to write up some notes on my talk and the other talks as well. I haven't posted slides from the talk, but it really wasn't much more than a condensed version of exa-related blog entries I've made, (and which are linked to in Adam's writeup).
One of the things I asked for in the talk is more benchmarks for 2D rendering---in particular real-world applications with benchmarking modes and micro-benchmarks distilled from real-world applications. Vincent Torri recently reminded me that Carsten "rasterman" Haitzler wrote render_bench a long time ago precisely to measure the performance of XRender, (and to compare it to his imlib2 software).
I hadn't run render_bench since I started playing with EXA and the
i965 chip, so it was definitely a worthwhile thing to do. Here are the
results I got (comparing XAA and EXA both against imlib2):
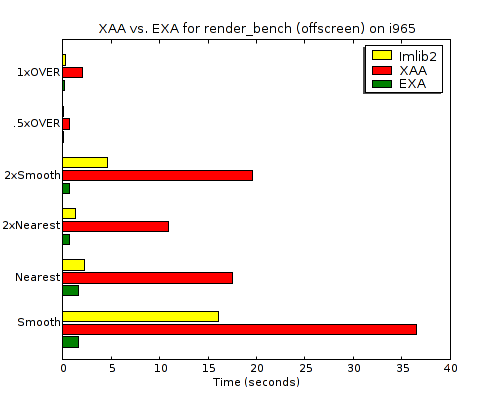
All of the numbers are from the same 2.13GHz dual-core Intel machine. But the absolute numbers aren't interesting anyway. The interesting part is the huge improvement in X Render performance going from XAA to EXA for the i965 device. It goes from 2-8 times slower than imlib2 to 1.3-12.9 times faster. Anyone interested in the raw times can view the EXA log and XAA log files.
One thing that would be useful is for someone to augment the framework to also test the same drawing operations through cairo. It would be good to verify that none of the cairo software layers get in the way of this performance, (I can imagine cairo doing something like setting up and tearing down XRender Picture objects rather than reusing them, but hopefully it will perform just as well).
And I should point out that this improvement is not due to anything I've done. This is basically just an upstream xserver tree, (it might have my glyph-pixmaps change but they are not relevant here). So kudos to the EXA hackers I mentioned in my talk, (Keith Packard, Zack Rusin, Eric Anholt, and Michel Dänzer). I definitely need to amend my what EXA gets right post to add image-scaling to window-copying and solid-fills.
This also isn't with any special hacks to the xf86-driver-intel source, (I'm using upstream commit 286f5df0b from Sep. 6). This benchmark clearly isn't hitting the same compositing slowness I'm seeing with glyph rendering and that might be because it's using larger images than the generally tiny images that are used for glyphs, (but I'm just guessing---I haven't looked closely).
Meanwhile, I am rewriting the driver to eliminate all the syncs and flushes when compositing to fix the glyph performance. I hope to have something worth sharing soon.
Finally, I also compared the results of evas_xrender_x11_test with
evas_software_x11_test. This is similar to the original render_bench,
but with a more real-world framework in place, (the evas canvas), as
opposed to just a micro benchmark. Here XRender/EXA did not fare as
well, scoring an evas benchmark score of 4.994 compared to the 10.418
of the software version. (Meanwhile XAA scored 4.840 but with some
noticeably incorrect results---the large scaled image came out just
black). The weaker performance here might very well be because the
evas tests do include text which render_bench does not, (but again I'm
just guessing and haven't looked closely).
Oh, and the evas snapshot I used for this test is
evas-0.9.9.023. I
tried to also test a newer snapshot such as
evas-0.9.9.041,
but it seems to not build the evas_*_test programs anymore. Perhaps
they're now available separately?