
Many readers have heard already, but it will be news to some that I recently changed jobs. After just short of 4 years with Red Hat, I've now taken a job working for Intel, (in its Open-source Technology Center). It was hard to leave Red Hat---I have only fond memories of working there, and I will always be grateful to Red Hat for first helping me launch a career out of working on Free Software.
Fortunately, as far as my free-software work is concerned, much of it will be unaffected by the job change. In fact, since I've been looking at X/2D/Intel driver graphics performance for the last year already, this job change should only help me do much more of that. And as far as cairo goes, I'll continue to maintain it, but I haven't been doing much feature development there lately anyway. Instead, the most important thing I feel I could do for cairo now is to continue to improve X 2D performance. And that's an explicit job requirement in my new position. So I think the job change will be neutral to positive for anyone interested in my free-software efforts.
As my first task at Intel, I took the nice HP 2510p laptop I was given on the first day, (which has i965 graphics of course), installed Linux on it, then compiled everything I needed for doing X development. I would have saved myself some pain if I had used these build instructions. I've since repeated that exercise with the instructions, and they work quite well, (though one can save some work by using distribution-provided development packages for many of the dependencies).
Also, since I want to do development with GEM, I built the drm-gem branches of the mesa, drm, and xf86-video-intel modules. That's as simple as doing "git checkout -b drm-gem origin/drm-gem" after the "git clone" of those three modules, (building the master branch of the xserver module is just fine). That seemed to build and run, so I quickly installed it as the X server I'm running regularly. I figured this would be great motivation for myself to fix any bugs I encountered---since they'd impact everything I tried to do.
Well, it didn't take long to find some performance bugs. Just switching workspaces was a rather slow experience---I could literally watch xchat repaint its window with a slow swipe. (Oddly enough, gnome-terminal and iceweasel could redraw similarly-sized windows much more quickly.) And it didn't take much investigation to find the problem since it was something I had found before, a big, blocking call to i830WaitSync in every composite operation. My old favorite, "x11perf -aa10text" was showing only 13,000 glyphs per second.
I had done some work to alleviate that before, and Dave Airlie had continued that until the call was entirely eliminated at one point. That happened on the old "intel-batchbuffer" branch of the driver. Recall that in January Eric and I had been disappointed to report that even after a recent 2x improvement, the intel-batchbuffer branch was only at 109,000 glyphs per second compared to 186,000 for XAA.
Well, that branch had about a dozen, large, unrelated changes in it, and poor Eric Anholt had been stuck with the job of cleaning them up and landing them independently to the master branch, (while also writing a new memory manager and porting the driver to it).
So here was one piece that just hadn't been finished yet. The driver was still just using a single vertex buffer that it allocates upfront---and a tiny buffer---just big enough for a single rectangle for a single composite operation. And so the driver was waiting for each composite operation to finish before reusing the buffer. And the change to GEM had made this problem even more noticeable. And Eric even had a partially-working patch to fix this---simply allocating a much larger vertex buffer and only doing the sync when wrapping around after filling it up. He had just been too busy with other things to get back to this patch. So this was one of those times when it's great to have a fresh new co-worker appear in the next cubicle asking how he could help. I took tested Eric's patch, broke it up into tiny pieces to test them independently, and Eric quickly found what was needed to fix it, (an explicit flush to avoid the hardware caching vertex-buffer entries that would be filled in on future composite calls).
So, with that in place the only thing left to decide was how large of a vertex buffer to allocate upfront. And that gives me an excuse to put in a performance plot:
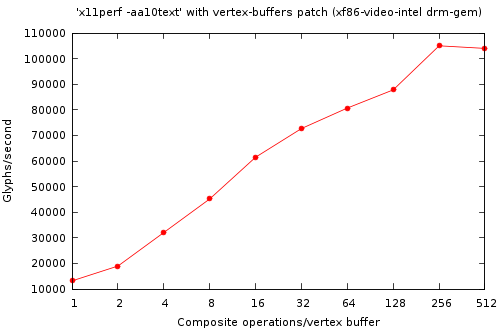
So the more the better, (obviously), until we get to 256 composite operations fitting into a single buffer. Then we start losing performance. So on the drm-gem branch, this takes performance from 13,000 glyphs/second to 100,000 glyphs/second for a 7.7x speedup. That's a nice improvement for a simple patch, even if the overall performance isn't astounding yet. It is at least fast enough that I can now switch workspaces without getting bored.
So I went ahead and applied these patches to the master branch as well. Interestingly, without any of the drm-gem branches, and even with the i830WaitSync call on every composite operation, things were already much better than in the GEM world. I measured 142,000 glyphs/second before my patch, and 208,000 glyphs/second after the patch. So only a 1.5x speedup there, but for the first time ever I'm actually measuring EXA text rendering that's faster than XAA text rendering. Hurrah!
And really, this is still just getting started. The patch I've described here is still just a bandaid. The real fix is to eliminate the upfront allocation and reuse of buffers. Instead, now that we have a real memory manager, (that's the whole point of GEM), we can allocated buffer objects as needed for vertex buffer, (and for surface state objects, etc.). That's the work I'll do next and it should let us finally see some of the benefits of GEM. Or if not, it will point out some of the remaining issues in GEM and we'll fix those right up. Either way, performance should just keep getting better and better.
Stay tuned for more from me, and look forward to faster performance from every Intel graphics driver release.