
A few months ago I reached the conclusion that remaining cairo performance problems were largely not in the cairo library itself, but were in the X server, its acceleration architectures, or in the X drivers for specific devices. So I started measuring with the cairo-perf suite of micro-benchmarks and I identified what appeared to be some potential problems. For example, there are OVER operations that should degenerate into simple blits but that seem to be running 2x slower than blits, (more on this later).
Before pursuing those in detail, (or after chasing a non-problem for too long), I decided to step back from micro benchmarks and instead look at some real-world tests with the Mozilla Trender suite to ensure I wasn't doing micro-optimization that wouldn't have any significant impact. It was at that time that I also switched my focus from an ATI r100, (which was just the graphics chip that happened to be in my laptop), to looking at the Intel 965 chip instead, (since Intel had donated one for me to work with).
The i965 is interesting because it's new, (ooh, shiny!), and coming from a company that actually supports the free software community by providing free software drivers. That support continues to improve as last week, Intel made technical documentation on the i965 available to myself and other Red Hat employees. (The documentation was made available under an existing Intel-Red Hat NDA which means I cannot share the documentation, but I can use the documentation to write, improve, and release free-software drivers.) I'm optimistic that Intel will be willing to setup a similar NDA with anyone interested in improving the drivers, and even better, that Intel will eventually convince itself it can share the documentation as freely as it is currently sharing its driver source code.
And actually, the work I've done in the last week hasn't strictly required the documentation at all. What has been necessary is to roll up my sleeves and get more familiar with the X server source code. I'm really grateful to Keith Packard, Eric Anholt, Dave Airlie, Kevin Martin, Michel Dänzer, Adam Jackson, Daniel Stone and others who have helped me get started here. There's really a very welcoming community of very intelligent people around the X server who are glad to help guide new people who want to help. And there's no shortage of things that can be done.
It is a large code base to get familiar with, (using "git grep" to find things helps a lot). And, being as old as it is, it does have lots of "moldy" aspects to the way it's coded, but it's not as bad as one might fear. So please, come join us if you're interested!
Guided by the problems showcased by the Mozilla test suite and the i965 driver, I decided that the most obviously underperforming operation is glyph compositing. And I also identified two underlying problems: excessive migration and synchronous compositing.
With the problems identified that concretely, I'm actually working on fixing problems now instead of just reporting them. And for this focused work, it makes sense to get back to micro-benchmarks for tracking the specific things I'm working on. So I started out with "x11perf -aa10text" to test glyph compositing performance. A more general operation than glyph compositing is image compositing, but it seems that x11perf has never acquired any Render-based image compositing benchmarks, (maybe that explains why some compositing performance regressions went unnoticed?). I did convince Keith to sit down and write some x11perf-based compositing tests, which I expect he'll push out shortly. And those tests should do a great job of highlighting the problems I seemed to see with cairo-perf where compositing with Over wasn't properly degenerating to blit performance when there is no source alpha.
In exchange, Keith convinced me to do some work to change the way glyph images are stored in the X server. Previously, glyph images have been chunks of system memory, which means they were off-limits for being used as part of any accelerated rendering. What EXA would do, is every time a glyph was to be rendered, it would first copy it into a video-memory Pixmap so that it could have some hope of accelerating it. So the same glyph data would get copied from system memory to video memory over and over again, (and likely overwhelm any performance advantage from doing "accelerated" compositing with the glyphs).
A fairly obvious solution is to move the canonical location for glyph data to be video-memory Pixmaps in the first place. This has a few potential problems:
Glyph images are sharable across the entire server, but Pixmaps are specific to each individual "screen" within the server.
The X server uses the system-memory glyph data to compare when a glyph is uploaded by a client that is identical to a glyph uploaded previously by another client, (using a simple XOR-based hash to do fewer comparisons---but always falling back to a full compare after matching the hash).
Recent work that Dave Airlie, Kristian Høgsberg, and Eric Anholt have been doing may result in there being a one-to-one relationship between Pixmaps and "buffer objects". And these buffer objects require page-alignment, so their minimal size will be 4k, (which could be quite excessive for small, 10x10 glyph).
Another concern before any of those is whether glyphs are even worth trying to accelerate in the first place. If they are small enough, might the overhead of involving the GPU be excessive and it would be better to simply let the CPU render them, (even if that requires some read-modify-write for the compositing)? For this concern, see the window-to-window copy results I just posted in what exa gets right. That shows that EXA (GPU based) copying can be 5x faster that NoAccel (CPU based) even with regions as small as 10x10. Add compositing to that, and the GPU should be just as fast, but the CPU should be slower. So we really should be able to win, even with fairly tiny glyphs.
So, how to tackle the other technical problems. Here's what I've come up with so far:
Per-screen Pixmaps: Suck it up for now. One, actually having multiple "screens" in the X server isn't common. Things like Xinerama that use one "screen" for multiple displays are much more common. So, I've written code that allocates one Pixmap per screen for every glyph. If this turns out to be a problem in practice, it would be quite trivial to create the Pixmaps lazily for all but one screen. And it would also be worthwhile, (but a much larger change), to lift the per-screen restriction for objects like Pixmaps.
System-memory data for avoiding hash collisions: The goal is to move the storage from system memory to a video-memory Pixmap. We lose, (by spending excess memory), if we still have to keep a system-memory image. To fix this, I've replaced the weak XOR-based hash with a cryptographically strong hash (SHA1) that will be (probabilistically) collision free. This does introduce a new dependency of the X server on the openssl library.
4k alignment constraints for buffer objects: This is likely a very real issue, but something I'd like to address later. Presumably we can alleviate the problem by pooling multiple glyphs within a single Pixmap, (or multiple Pixmaps within a single buffer object), or whatever necessary.
So, given those approaches, I've written a series of 7 patches implementing glyph storage as pixmaps.
On my i965 the patch series doesn't impact NoAccel or XAA performance considerably, but does improve EXA performance a bit. Here are the results for x11perf -aa10text and -aa24text:
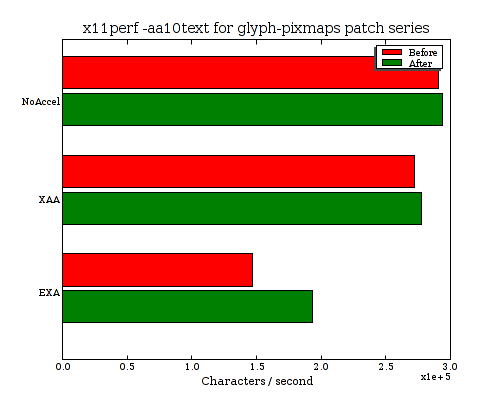
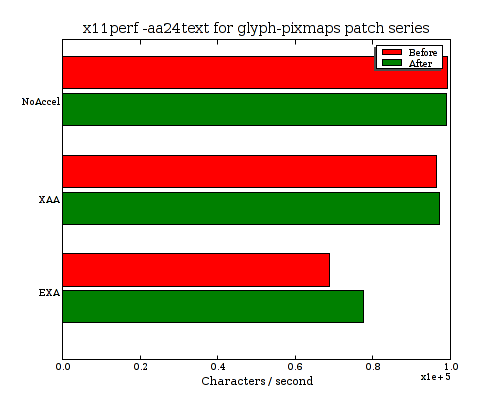
Now, that was quite a bit of work, (and way too long of a blog post already), but not yet any huge performance improvement. But I think this is a good, and necessary step toward getting to fast compositing of glyphs. Here are before-and-after performance charts for the aa10text test with links to profiles:
We can see that some copying was eliminated, (note the fbBlt contribution to libfb in the before profile has disappeared completely). But there's still some migration going on somewhere, (see the exaMemCpyBox stuff as well as a bunch of software rendering happening in pixman). The assumption I'm operating on is that we should be able to eliminate migration and software rendering entirely. The hardware is very capable, very flexible and programmable, and we have all the programming documentation. So there should just be a little work here to see what's still falling back to software and eliminating it.
Then, obviously, there's still the synchronous compositing problem. I'm guessing that's where the big time spent in the kernel is coming from. So imagine half of the pixman and kernel chunks going away, along with 25% of the libexa chunk and over half of libc, (that looks like the obvious hotspots from excessive migration synchronous compositing). And then EXA text would at least catch up to XAA and NoAccel.
But if we only match the performance, we're wasting our time and should just use the NoAccel code paths in the first place. But I'm optimistic that there's still quite a bit of optimization that could happen after that. We'll see of course.